大营销分布式系统--从零开始实现数据库分库分表组件
随着业务的发展,营销系统的数据量和访问量会不断增加。单个数据库和表会成为系统的瓶颈,导致查询速度变慢、系统响应延迟增加,甚至可能引发数据库的崩溃。所以如何提高数据库的读写性能和扩展能力来处理不断增加的数据库请求和数据量成为一个问题。单个数据库和表物理服务机资源有限,所以增加多个数据库是一个常用的方式(注意:MySQL主从备份和Mysql分库分表是两个不同的概率)。常见的方式是对数据库进行分库分表。
1. 分库分表基础知识补充
对单个数据库进行拆分,主要有两个方式,水平拆分和垂直拆分。
1.1 垂直拆分
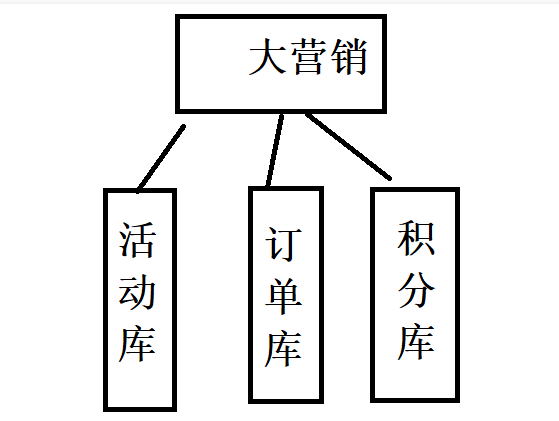
垂直拆分为垂直分库和垂直分表,主要按功能模块进行拆分。比如分为活动库、订单库、积分库等。
1.1.1 垂直分库
垂直分库是一种简单的逻辑分割方式,比如我们有多个表,将每个表都单独创建一个数据库。其优点就是可以根据具体业务进行分割,对于后续扩展比较方便。当时垂直分库的缺点在于,不同业务的数据量和访问量不一,直接进行垂直分库会导致资源利用不均匀。
1.1.2 垂直分表
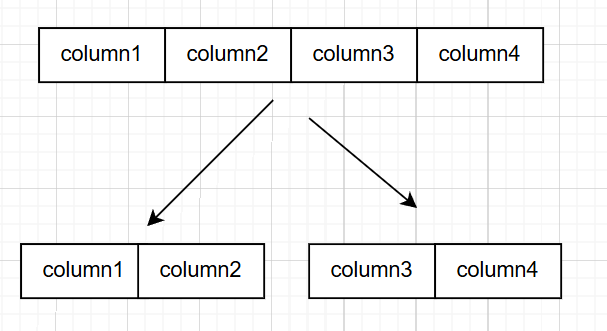
垂直分表是根据表中字段来进行划分。通常来说一张数据库表包含了实体的所有字段,随着业务的发展,当个数据表将及其庞大。而根据二八法则来说,表中大概有20%的数据字段是常用的(热数据),80%的字段是不常用的(冷数据),所以垂直分表就是根据表中字段使用频率将表分为多个表。
1.1.3 总结
垂直拆分的优点:
- 随着业务进行分割,方便管理和扩展
- 能提升性能,实现冷热数据的分离
垂直拆分的缺点:
- 部分业务表无法join
- 单表数据量膨胀问题还在
- 分布式事务
1.2 水平拆分
水平拆分又分为库内分表和分库分表,来解决数据库表中存在的大数据量问题。
1.2.1 库内分表
简单来说,如果一个数据库表里面的记录量大于一定记录,就将记录量分为多个部分,比如将1千万的记录,前5百万分为一部分,后5百万分为一部分。
补:阿里推荐超过500万行、百度推荐1000万行分表
1.2.2 库内分表的实现策略
接下来是单独从数据库的角度去分析分表,逻辑上来说还是一个表,只是在物理层变成多个分区。
1.2.2.1 HASH(哈希)
基于将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。HASH分区会将数据平均分布。HASH可以由用户定义
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY HASH(YEAR(createtime))
PARTITIONS 10;
1.2.2.2 RANGE(范围)
基于属于一个给定连续区间的列值,把多行分配给同一个分区,这些区间要连续且不能相互重叠,使用VALUES LESS THAN操作符来进行定义。
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE(gwcode) (
PARTITION P0 VALUES LESS THAN(101) ,
PARTITION P1 VALUES LESS THAN(201) ,
PARTITION P2 VALUES LESS THAN(301) ,
PARTITION P3 VALUES LESS THAN MAXVALUE
);
1.2.2.3 LIST(预定义列表)
RANGE是指一个连续的分区,而LIST指的是离散的值为分区。
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY LIST(`gwcode`) (
PARTITION P0 VALUES IN (46,77,89) ,
PARTITION P1 VALUES IN (106,125,177) ,
PARTITION P2 VALUES IN (205,219,289) ,
);
1.2.2.4 KEY (键值)
和HASH分区类似,只是hash函数由数据库提供。
drop table if EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DateTime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY KEY(createtime)
PARTITIONS 10;
1.2.2.5 Composite(复合模式)
也叫二级分区,由以上多个分区方式组合。
DROP TABLE IF EXISTS `t_userinfo`;
CREATE TABLE `t_userinfo` (
`id` int(10) unsigned NOT NULL,
`personcode` varchar(20) DEFAULT NULL,
`personname` varchar(100) DEFAULT NULL,
`depcode` varchar(100) DEFAULT NULL,
`depname` varchar(500) DEFAULT NULL,
`gwcode` int(11) DEFAULT NULL,
`gwname` varchar(200) DEFAULT NULL,
`gravalue` varchar(20) DEFAULT NULL,
`createtime` DATETIME NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE (YEAR(createtime)) -- 按年份进行 RANGE 分区
SUBPARTITION BY KEY (id) -- 在每个 RANGE 分区中按 id 进行 KEY 分区
SUBPARTITIONS 4 ( -- 每个 RANGE 分区再划分为 4 个子分区
PARTITION p2020 VALUES LESS THAN (2021), -- 2020年
PARTITION p2021 VALUES LESS THAN (2022), -- 2021年
PARTITION p2022 VALUES LESS THAN (2023), -- 2022年
PARTITION p_max VALUES LESS THAN MAXVALUE -- 2023年及以后
);
1.2.3 分库分表
以上的分区分表任然是在单个物理机上进行,会受限于单机性能限制。所以需要进一步分库分表,将不同的数据表进行水平切分到不同的物理机上。
1.2.4 总结
优点:
- 解决了数据库的单个数据表数据量过大的问题
缺点:
- 分布式事务问题
- 跨表Join
- 数据管理问题
1.3 常用的分库分表组件
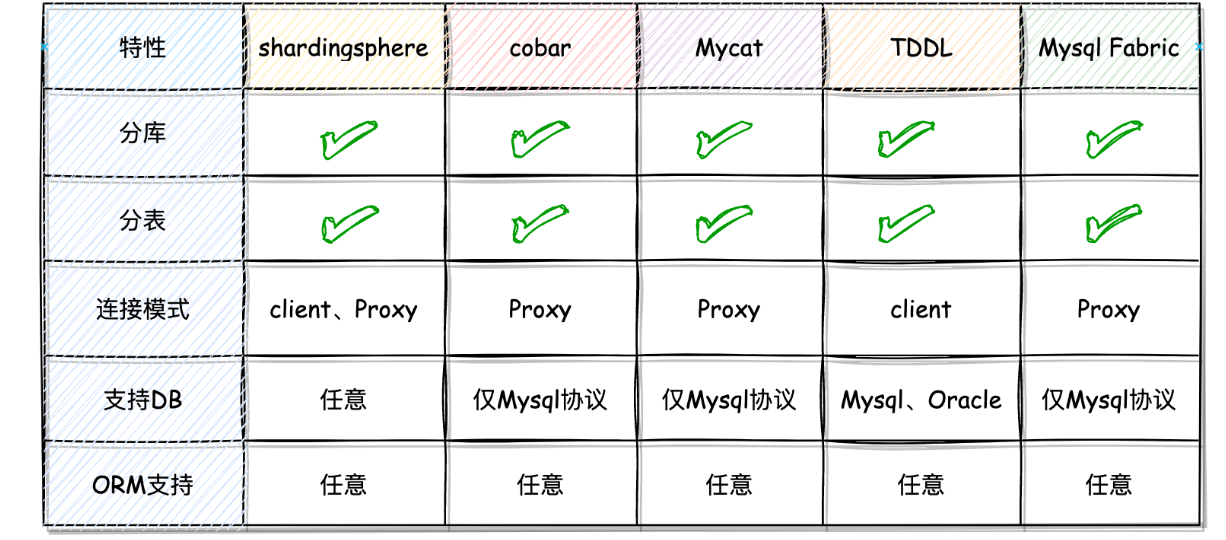
对于分库分表来说,通过会由分库分组组件来做。常见有两种方式,一种作为Client(分库分表实现随同应用代码一起访问实际的数据库),另一种为Proxy(分库分表组件在应用和数据库之间做分发)。
常用的Sharding-JDBC就是Clinet模式,MyCat是Proxy模式。
2. 分库分表实现
本次实现的分库分表组件为Client模式。
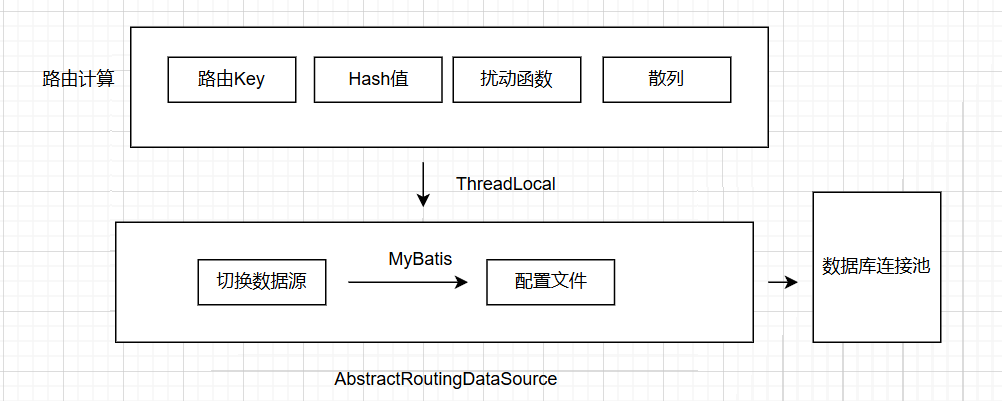
分库分表的核心目的是把数据均匀的散列到各个库表中,减轻单库表的事务操作压力。整体数据库架构主要包括以下内容:
- 数据库连接池配置:分库分表通过配置文件按需配置数据库连接源,在连接池的集合中进行动态切换操作。
- AbstractRoutingDataSource: 用于动态切换数据源的Spring服务类
- 路由计算:获取分库分表字段,通过Hash计算以及扰动达到尽可能的散列,使数据尽可能分布到各个库表中。
2.1 路由注解定义
为 了切面提供切点,通过获取方法入参属性的字段,作为路由字段
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouter {
String key() default "";
}
另一种注解,提供Mybatis-Plus的标记作为是否解析的标致
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouterStrategy {
boolean splitTable() default false;
}
2.2 路由信息处理
设置本地线程记录分库、分表的路由结果
public class DBContextHolder {
private static final ThreadLocal<String> dbKey = new ThreadLocal<String>();
private static final ThreadLocal<String> tbKey = new ThreadLocal<String>();
//...get/set
}
2.3 动态数据源
继承的AbstractRoutingDataSource来自Spring-JDBC, 根据当前设置的路由设置对应数据库。
public class DynamicDataSource extends AbstractRoutingDataSource {
@Value("${mini-db-router.jdbc.datasource.default}")
private String defaultDataSource;
public DynamicDataSource() {
}
protected Object determineCurrentLookupKey() {
return null == DBContextHolder.getDBKey() ? this.defaultDataSource : "db" + DBContextHolder.getDBKey();
}
}
配置加载和创建数据源
@Configuration
public class DataSourceAutoConfig implements EnvironmentAware {
private Map<String, Map<String, Object>> dataSourceMap = new HashMap<>();
private int dbCount; //分库数
private int tbCount; //分表数
private String routerKey; //路由Key
@Bean
public DBRouterConfig dbRouterConfig() {
return new DBRouterConfig(dbCount, tbCount, routerKey);
}
@Override
public void setEnvironment(Environment environment) {
String prefix = "router.jdbc.datasource.";
dbCount = Integer.valueOf(environment.getProperty(prefix + "dbCount"));
tbCount = Integer.valueOf(environment.getProperty(prefix + "tbCount"));
String dataSources = environment.getProperty(prefix + "list");
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
}
@Bean
public DataSource createDataSource() {
// 创建数据源
Map<Object, Object> targetDataSources = new HashMap<>();
for (String dbInfo : dataSourceMap.keySet()) {
Map<String, Object> objMap = dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo, new DriverManagerDataSource(objMap.get("url").toString(), objMap.get("username").toString(), objMap.get("password").toString()));
}
// 设置数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
return dynamicDataSource;
}
}
-
setEnvironment读取自定义的YAML配置
-
dataSource根据设置的环境读取其中的信息,创建数据源
-
dataRouterConfig根据当前的配置生成Bean供后续使用
2.4 数据库路由计算
2.4.1 AOP切面
设置AOP切面,做路由设置
@Aspect
@Component("db-router-point")
public class DBRouterJoinPoint {
private Logger logger = LoggerFactory.getLogger(DBRouterJoinPoint.class);
private DBRouterConfig dbRouterConfig;
private IDBRouterStrategy dbRouterStrategy;
public DBRouterJoinPoint(DBRouterConfig dbRouterConfig, IDBRouterStrategy dbRouterStrategy) {
this.dbRouterConfig = dbRouterConfig;
this.dbRouterStrategy = dbRouterStrategy;
}
@Pointcut("@annotation(cn.bugstack.middleware.db.router.annotation.DBRouter)")
public void aopPoint() {
}
@Around("aopPoint() && @annotation(dbRouter)")
public Object doRouter(ProceedingJoinPoint jp, DBRouter dbRouter) throws Throwable {
String dbKey = dbRouter.key();
if (StringUtils.isBlank(dbKey)) throw new RuntimeException("annotation DBRouter key is null!");
// 计算路由
String dbKeyAttr = getAttrValue(dbKey, jp.getArgs());
this.dbRouterStrategy.doRouter(dbKeyAttr);
logger.info("数据库路由 method:{} dbIdx:{} tbIdx:{}", getMethod(jp).getName(), dbIdx, tbIdx);
// 返回结果
try {
// 执行目标方法
return jp.proceed();
} finally {
this.dbRouterStrategy.clear();
}
}
private Method getMethod(JoinPoint jp) throws NoSuchMethodException {
Signature sig = jp.getSignature();
MethodSignature methodSignature = (MethodSignature) sig;
return jp.getTarget().getClass().getMethod(methodSignature.getName(), methodSignature.getParameterTypes());
}
public String getAttrValue(String attr, Object[] args) {
String filedValue = null;
for (Object arg : args) {
try {
if (StringUtils.isNotBlank(filedValue)) break;
filedValue = BeanUtils.getProperty(arg, attr);
} catch (Exception e) {
logger.error("获取路由属性值失败 attr:{}", attr, e);
}
}
return filedValue;
}
}
- dbRouterConfig , 注入数据库路由配置信息
- aopPoint,定义的切点, 后续注解在DAO中,会被切面拦截
- doRouter, 在切面拦截执行
2.4.2 路由计算
定义进行route的接口, 并采用HASH实现
public interface IDBRouterStrategy {
void doRouter(String var1);
void setDBKey(int var1);
void setTBKey(int var1);
int dbCount();
int tbCount();
void clear();
}
public class DBRouterStrategyHashCode implements IDBRouterStrategy {
private Logger logger = LoggerFactory.getLogger(DBRouterStrategyHashCode.class);
private DBRouterConfig dbRouterConfig;
public DBRouterStrategyHashCode(DBRouterConfig dbRouterConfig) {
this.dbRouterConfig = dbRouterConfig;
}
public void doRouter(String dbKeyAttr) {
// 计算路由
int size = this.dbRouterConfig.getDbCount() * this.dbRouterConfig.getTbCount();
// 扰动函数
int idx = size - 1 & (dbKeyAttr.hashCode() ^ dbKeyAttr.hashCode() >>> 16);
// 库表索引
int dbIdx = idx / this.dbRouterConfig.getTbCount() + 1;
int tbIdx = idx - this.dbRouterConfig.getTbCount() * (dbIdx - 1);
// 设置到 ThreadLocal
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
DBContextHolder.setTBKey(String.format("%03d", tbIdx));
this.logger.debug("数据库路由 dbIdx:{} tbIdx:{}", dbIdx, tbIdx);
}
public void setDBKey(int dbIdx) {
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
}
public void setTBKey(int tbIdx) {
DBContextHolder.setTBKey(String.format("%03d", tbIdx));
}
public int dbCount() {
return this.dbRouterConfig.getDbCount();
}
public int tbCount() {
return this.dbRouterConfig.getTbCount();
}
public void clear() {
DBContextHolder.clearDBKey();
DBContextHolder.clearTBKey();
}
}
- doRouter , 具体实现路由计算的函数
- clear, 清理当前的路由设置
2.4.3 哈希扰动
int idx = size - 1 & (dbKeyAttr.hashCode() ^ dbKeyAttr.hashCode() >>> 16);
- 通过对哈希码自身与其高16位异或,从而生成一个新的哈希值。这种方式旨在提高低位哈希结果的随机性。
- 通过
&操作将扰动后的哈希值限制在[0, size-1]的范围内
优势:
1. 默认的hashCode生成的值在大规模数据中会有碰撞几率,通过扰动增加随机性降低此几率。
- 避免哈希值过于集中的集中式分布,从而提高数据分片、路由的均匀性和性能
哈希扰动在HASHMAP中也进行了应用
2.4.4 MyBatis-Plus拦截器动态解析来分表
除了通过AOP来实现拦截来解析SQL,还能通过Mybatis-plus的拦截器来设置表的路由。
@Intercepts({
@Signature(
type = StatementHandler.class,
method = "prepare",
args = {Connection.class, Integer.class}
)
})
public class DynamicMybatisPlugin implements Interceptor {
}
具体逻辑,就是判断当前的Dao接口的类是否含有注解,如果有,就使用mybatis进行sql改写。
public Object intercept(Invocation invocation) throws Throwable {
StatementHandler statementHandler = (StatementHandler)invocation.getTarget();
MetaObject metaObject = MetaObject.forObject(statementHandler, SystemMetaObject.DEFAULT_OBJECT_FACTORY, SystemMetaObject.DEFAULT_OBJECT_WRAPPER_FACTORY, new DefaultReflectorFactory());
MappedStatement mappedStatement = (MappedStatement)metaObject.getValue("delegate.mappedStatement");
String id = mappedStatement.getId();
String className = id.substring(0, id.lastIndexOf("."));
Class<?> clazz = Class.forName(className);
DBRouterStrategy dbRouterStrategy = (DBRouterStrategy)clazz.getAnnotation(DBRouterStrategy.class);
if (null != dbRouterStrategy && dbRouterStrategy.splitTable()) {
BoundSql boundSql = statementHandler.getBoundSql();
String sql = boundSql.getSql();
Matcher matcher = this.pattern.matcher(sql);
String tableName = null;
if (matcher.find()) {
tableName = matcher.group().trim();
}
assert null != tableName;
String replaceSql = matcher.replaceAll(tableName + "_" + DBContextHolder.getTBKey());
Field field = boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql, replaceSql);
field.setAccessible(false);
return invocation.proceed();
} else {
return invocation.proceed();
}
}
2.5 总结
- 自动加载自定义配置 yml 创建多数据源
- 有切面拦截需要路由的 DAO 方法
- 做相应的路由散列计算
- 由继承 AbstractRoutingDataSource 的实现类处理数据源动态切换
总结
虽然分库分表组件能方便实现分库分表,但深入理解数据库优化任然是比较重要的。